You might think it sounds impossible if I were to tell you that a game of peek-a-boo could alter the course of history. I’m here to demonstrate that it isn’t, though. Scientists have shown that child health and development, particularly the development of their brains, depend greatly on the first five years of life. When Thinuka (My Son) was born, he was a little baby who frequently cried. But as he’s gotten older, he’s begun to chuckle and make silly sounds. Even though we can see and hear these changes, there is much more going on internally. Younger than at any other age, our brains grow the quickest.
But in order for this growth to be healthy, they need your assistance. Children’s minds and general growth depend on five crucial factors: relating to others, conversing, playing, maintaining a healthy home, and participating in a community. These things all support them in realizing their greatest potential. Scientists refer to this as “serve and return,” which is just a fancy way of stating that when you interact with children, talk to them, and play with them, it strengthens their bonds with one another and teaches them vital life lessons that they’ll need as they become older. For instance, copycat games foster empathy and imagination, whereas name games foster vocabulary and focus. And activities like peekaboo actually strengthen their memory and confidence.
But it’s crucial to keep in mind that children require these connections frequently and early. Children may become confused and stressed when the link is severed. Adults can occasionally use their devices, but children are predisposed to look for meaningful connections. Therefore, it’s crucial to schedule time for play and interaction with your kids. And it goes beyond the time that they spend together. The calibre of that time is very important. So put your electronics away, look your kids in the eye, and be fully present with them.
Making a healthy home for your children is also crucial. This entails offering a secure atmosphere with an abundance of food, clothing, and affection. Additionally, it’s crucial to be a part of a community. It provides kids with a sense of community and teaches them how to participate in something bigger than themselves.
So what can you do to influence a child’s life in a positive way? Making time for play and interaction with your kids can be a good place to start. Also, keep in mind that it’s not only about how much time you spend together. The calibre of that time is very important. Be present, make eye contact, and put your devices away. Make a healthy home for your kids and give them a sense of belonging in the neighbourhood. The development of a child and, ultimately, the type of adult they will become, can be greatly influenced by these modest activities.
ChatGPT, or the “Conversational Generative Pre-training Transformer,” is a powerful language model developed by OpenAI that has the ability to generate human-like text. It has been trained on a massive amount of text data and can generate text in a wide variety of languages and styles. In this blog post, we will explore how ChatGPT can be used to improve your coding skills.
One of the most obvious ways that ChatGPT can be used to improve your coding skills is by helping you write better code. ChatGPT can be used to generate code snippets and entire programs based on a given prompt. For example, if you need to write a program to sort a list of numbers, you can provide ChatGPT with a prompt such as “Write a program to sort a list of numbers using the bubble sort algorithm” and it will generate a complete program for you. This can save you a lot of time and effort when working on a project, and can also help you learn new programming concepts and techniques.
Another way that ChatGPT can be used to improve your coding skills is by helping you understand and troubleshoot existing code. ChatGPT can be used to generate explanations and documentation for existing code, which can make it easier for you to understand how it works. Additionally, ChatGPT can be used to generate code to fix bugs in existing code. For example, if you have a program that is crashing and you don’t know why, you can provide ChatGPT with a prompt such as “Write a program to fix a crash in an existing program” and it will generate code that can fix the problem.
In addition to these benefits, ChatGPT can also be used to improve your coding skills by helping you learn new programming languages. ChatGPT can be used to generate code in a wide variety of languages, which can make it easier for you to learn a new language. Additionally, ChatGPT can be used to translate code from one language to another, which can be especially useful if you need to work on a project that uses a language you’re not familiar with.
ChatGPT can also be used to improve your coding skills by helping you improve your coding style. ChatGPT can be used to generate code that follows best practices and coding conventions for a given programming language. Additionally, ChatGPT can be used to generate code that is efficient and easy to read. This can be especially useful if you’re working on a large project with multiple developers, as it will make it easier for everyone to understand and work on the code.
In conclusion, ChatGPT is a powerful tool that can be used to improve your coding skills in a variety of ways. Whether you’re a beginner learning to code for the first time or an experienced developer looking to improve your skills, ChatGPT can help you write better code, understand and troubleshoot existing code, learn new programming languages, and improve your coding style. With the help of ChatGPT, you can save time and effort, and become a more efficient and effective coder.
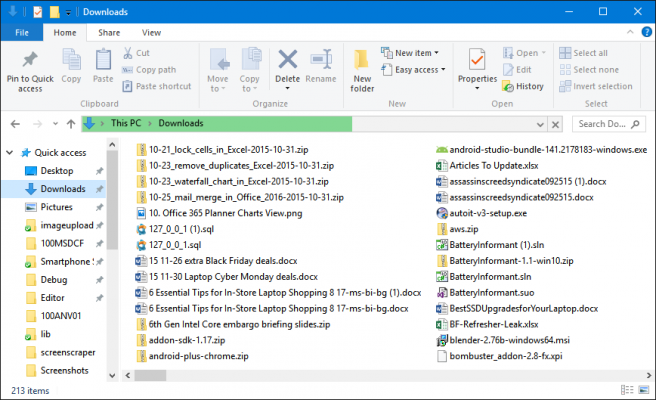
We download many things on an average day. It may be software that you need, maybe a PDF file, maybe an image, or maybe an MP3 file. It can be anything based on what you need. We all do this.
Now, just take a moment and go visit your Download directory…
How much file does it contain? if you want to find a certain file, does it seems easy? for me, it’s time-consuming and I have so many things in my download folder.
All of us, in many ways, like to be organized and keep our stuff in a certain order. At least we keep our PC Desktop organized.🙂
If you try to organize your Download folder manually it will take a lot of effort and time.
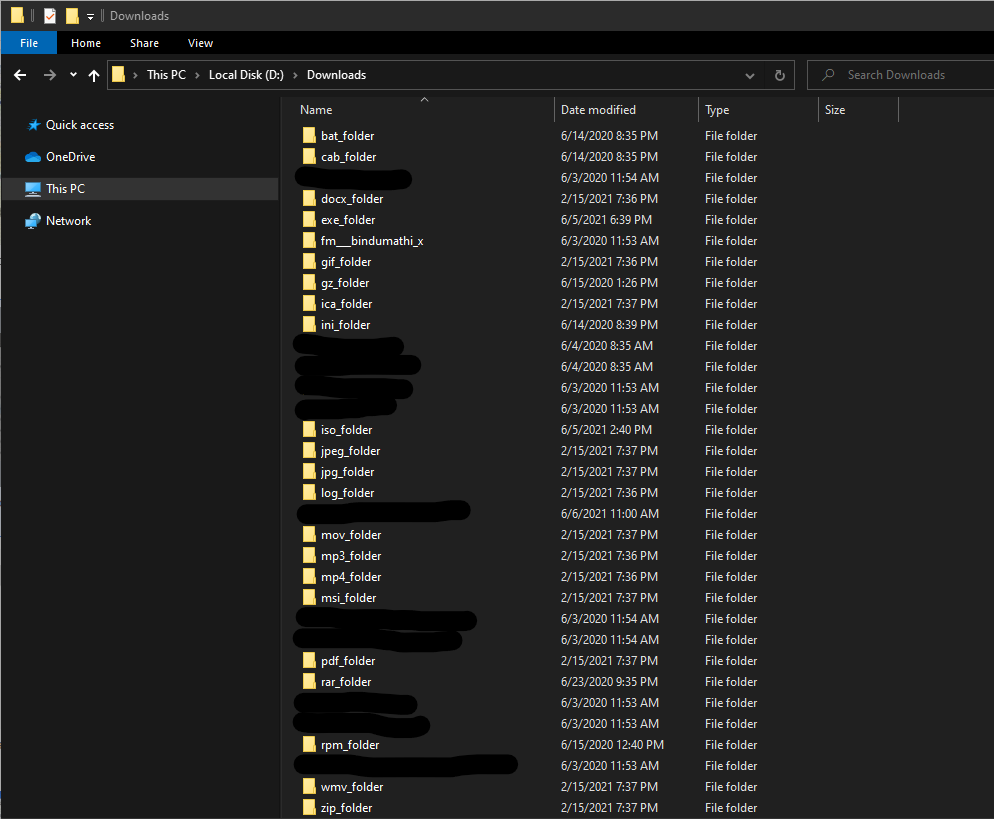
Now, how about if we have a way of getting this messy Download folder organized based on the file type? Move all the files to a folder based on its extension.
Not only that, How about if we can move a downloaded file to a specific folder at the moment it completes the download?
How cool is that?
I also had these questions and thoughts too.
I wanted to automate this so that I will not have to think about this again.
Following simple Python scrip will do exactly what I wanted. I will explain it to you so that you also will understand it and apply it to your need.
Let’s start.
Libraries Used
We only use the Python Standard Libraries for this and no need to install extra libraries.
Our Imports
We mainly use the os library to access the filesystem, shutil library to move and copy files, and the time library to manage our intervals within the main loop.
from os import listdir
from os.path import isfile, join
import os
import shutil
import time
Set our Variables
Now we define our variables which we will use within the script. In this way, it’s easy for us to manage those when we need changes.
Here we need a variable to store our source location which is the Download folder, then we need another variable to store our destination location, in here you can give any location you desire to have your downloads organized.
We will now create a method to store our logic and code for the manipulation of files in the Download directory.
def sort_files_in_a_folder(mypath):
now we need to collect the full path of all the files in the Download directory so that we can loop them later in our script. For this, we use the following line of code.
files = [file_name for file in listdir(mypath) if isfile(join(mypath, file_name))]
in above, we loop through all the files in the source directory while checking the validity of the file and assigning it to the file array.
This is why I love Python. Just one line of code, we collected all the file paths to an array.
Now we need to loop through these files to arrange them according to its extension. We need two for loops. One is to create our file extension array, our file type folder dictionary, and creating the folder structure on our destination location.
The second loop is to move the files from source to destination folders based on file extension.
First for Loop
In this, we loop through all the files in our files array. we split the file using dot(.) to get the file extension. Here there could be dots within the file name also, so we use -1 here file.split(‘.’)[-1], to get the last item of the array which is our extension.
for file in files:
filetype = file.split('.')[-1]
After that, we need to make sure that we do not move .tmp files as those are the temporary files created for ongoing downloads. if we move them, our downloads will fail. Hence we check whether the extensions on file_type_variation_list and filetype do not equal to tmp.
if filetype not in file_type_variation_list and filetype != "tmp":
Once the check is completed if that is a new extension, we then need to add it to our extension array file_type_variation_list.
file_type_variation_list.append(filetype)
Now, we need to create our new folder path in order to create our destination location. Also, we need to populate our dictionary variable and map the extension to its folder path. Once done, we use an if condition to check whether the folder exists or not. If not, then we create the folder.
This loop is to find the file extension and move the file to the destination location. Here I have introduced a try block to avoid script crashes if there are issues that occurred during the file move.
We generate the source file path using mypath variable and file variable and get the file extension as we described in the previous loop, then check the new location on our dictionary variable. Finally, we move the file from a source location to a destination.
for file in files:
src_path = mypath + '/' + file
filetype = file.split('.')[-1]
if filetype in filetype_folder_dict.keys():
dest_path = filetype_folder_dict[str(filetype)]
try:
shutil.move(src_path, dest_path)
print(src_path + '>>>' + dest_path)
except shutil.Error as ex:
pass
Our Main Loop
This is the main loop and it keeps running. It checks the file count in the Download folder to determine whether a new file was downloaded. If a new file is downloaded, the old count and the new count will not match and then it calls our method above described to move that file to the destination.
while True:
NumberOfFiles = len(os.listdir(sourceFolder))
time.sleep(20)
OldNumber = NumberOfFiles
NumberOfFiles = len(os.listdir(sourceFolder))
if NumberOfFiles != OldNumber:
sort_files_in_a_folder(sourceFolder)
Full Script
Here I have attached the full script.
from os import listdir
from os.path import isfile, join
import os
import shutil
import time
sourceFolder = "C:\\Users\\User\\Downloads"
file_type_variation_list = []
filetype_folder_dict = {}
destination_root = "D:\\Downloads"
def sort_files_in_a_folder(mypath):
files = [file_name for file in listdir(mypath) if isfile(join(mypath, file_name))]
for file in files:
filetype = file.split('.')[-1]
if filetype not in file_type_variation_list and filetype != "tmp":
file_type_variation_list.append(filetype)
new_folder_name = destination_root + '/' + filetype + '_folder'
filetype_folder_dict[str(filetype)] = str(new_folder_name)
if os.path.isdir(new_folder_name):
continue
else:
os.mkdir(new_folder_name)
for file in files:
src_path = mypath + '/' + file
filetype = file.split('.')[-1]
if filetype in filetype_folder_dict.keys():
dest_path = filetype_folder_dict[str(filetype)]
try:
shutil.move(src_path, dest_path)
print(src_path + '>>>' + dest_path)
except shutil.Error as ex:
pass
while True:
NumberOfFiles = len(os.listdir(sourceFolder))
time.sleep(20)
OldNumber = NumberOfFiles
NumberOfFiles = len(os.listdir(sourceFolder))
if NumberOfFiles != OldNumber:
sort_files_in_a_folder(sourceFolder)
Conclusion
Create a .bat file in order to add this to Windows Scheduler so that It listens to changes to the Download folder, which will trigger our script.
Everyone loves to listen to music. Sometimes you want to download your favorite song mp3 or your favorite album mp3. Downloading hundreds of mp3 files manually was…tiresome.
One day while I was downloading my favorite songs from an MP3 website, a question popped up in my mind: Why am I downloading all these files manually? That’s when I started thinking of writing an automation script for this.
Sounds like fun work to me, as I was working on some web scraping projects at that time. the idea was to input the artist name, and it scraped the source code for mp3 files from that artist and download them onto my HDD by creating a separate folder with the artist name. Let’s dive in and understand each step.
First thing – First
We need one extra python library ‘BeautifulSoup’ which we need to install before we move further. Following is the instruction on how to install it.
pip install beautifulsoup4
Now we all set. Let’s dig in
Import Required Libraries to your python program
From the library we just installed we import the BeautifulSoup module to our program. We use the BeautifulSoup library to parse the HTML content of the site URL.
from bs4 import BeautifulSoup
Then we need to import another library to handle the HTTP request. For that, we use the requests module from python.
import requests
We have now imported libraries that need us to scrape the site and download the MP3 files. Now we need two more python libraries that we use to access the os file system to write our MP3 files.
import os
import sys
Now we have all the libraries and modules imported to our program.
We’ll set few Variables
We need the user to input the artist’s name in order to download the MP3 files for that artist. For that, we need a string variable to accept system inputs. module sys provide a method to read input values and store them in a string array. we need to provide the correct index to ready the user input. For us, it’s the 1st position of the array.
artist_name = sys.argv[1]
Now we need four more string variables to store directory name, URL with artist name, file extension that we are going to download, and one for storing the file name.
Using a simple if block we can check whether the user has entered the artist name or not. If our artist_name variable is not empty, that means the user has provided the artist name. If the user has not provided any input then the program will notify the user with a message “Artist name needs to provide.” and terminate the program
if artist_name is not None:
#we will write our code here.
else:
print('Artist name needs to provide.')
Read and Parse the HTML
Using request.get() method we can read the URL and after that, we convert it to text so that we can give it as an input to our HTML parser (BeautifulSoup).
Now, we have our HTML code. What we need to do is find all the <a> tags on the page. This is where we find the href property which has the URL for Artists’ Home Page. Once we collect all the <a> tags we need to loop each one of them with a condition in place to find the URLs where the artist’s name is present. If we find one anchor tag where href value is set to a URL with the artist name, then we need to read that URL and have to do the Read and Parse steps to that URL too. This means now we have navigated to the Artists home page where all the MP3s are listed for that artist.
for node in soup.find_all('a'):
if node.get('href').find(artist_name) != -1:
url2 = node.get('href') + '/'
page2 = requests.get(url2).text
soup2 = BeautifulSoup(page2, 'html.parser')
Loop all the Anchor Tags in Artist Home Page
Now we have the HTML source for Artist’s home page, we need to find the <a> tags which contain the link to the MP3 file. Once we find it, we need to create the folder with Artist’s name and download the MP3 file to that location. Here I have used a try block to capture any errors while downloading and ignore them to move to the next URL. We do not want our program to stop if there is one broken link to the MP3 file.
for node2 in soup2.find_all('a'):
if node2.get('href').endswith(ext):
try:
if not os.path.exists(dirname):
os.mkdir(dirname)
for txt in node2.get('href').split('/'):
if txt.endswith(ext):
filename = txt
r = requests.get(node2.get('href'), allow_redirects=True)
os.chdir('C:/Python/' + dirname)
open(filename, 'wb').write(r.content)
os.chdir('C:/Python/')
except IndexError:
continue
Other Sites
While trying to download MP3s from another website, I realized that the source codes were different. Hence, the links had to be dealt with differently. Since I had already parsed the URL, I knew its source and had to do a few tweaks to the program to make it work.
And there it was! My very own MP3 downloading web scraping tool. Why waste hours downloading files manually when you can copy-paste a link and let Python do its magic?
Here’s what my overall code looked like:
from bs4 import BeautifulSoup
import requests
import os
import sys
artist_name = sys.argv[1]
dirname = artist_name
url = 'https://www.sinhalasongs.lk/sinhala-songs-download/' + artist_name + '/'
ext = 'mp3'
filename = ''
if artist_name is not None:
page = requests.get(url).text
soup = BeautifulSoup(page, 'html.parser')
for node in soup.find_all('a'):
if node.get('href').find(artist_name) != -1:
url2 = node.get('href') + '/'
page2 = requests.get(url2).text
soup2 = BeautifulSoup(page2, 'html.parser')
for node2 in soup2.find_all('a'):
if node2.get('href').endswith(ext):
try:
if not os.path.exists(dirname):
os.mkdir(dirname)
for txt in node2.get('href').split('/'):
if txt.endswith(ext):
filename = txt
r = requests.get(node2.get('href'), allow_redirects=True)
os.chdir('C:/Python/' + dirname)
open(filename, 'wb').write(r.content)
os.chdir('C:/Python/')
except IndexError:
continue
else:
print('Artist name needs to provide.')
Want to try it? Feel free to fork, clone, and star it on my Github. Have ideas to improve it? Create a pull request!