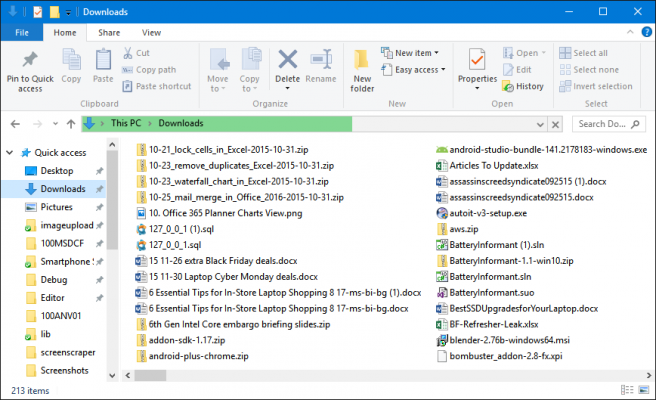
We download many things on an average day. It may be software that you need, maybe a PDF file, maybe an image, or maybe an MP3 file. It can be anything based on what you need. We all do this.
Now, just take a moment and go visit your Download directory…
How much file does it contain? if you want to find a certain file, does it seems easy? for me, it’s time-consuming and I have so many things in my download folder.
All of us, in many ways, like to be organized and keep our stuff in a certain order. At least we keep our PC Desktop organized.🙂
If you try to organize your Download folder manually it will take a lot of effort and time.
Now, how about if we have a way of getting this messy Download folder organized based on the file type? Move all the files to a folder based on its extension.
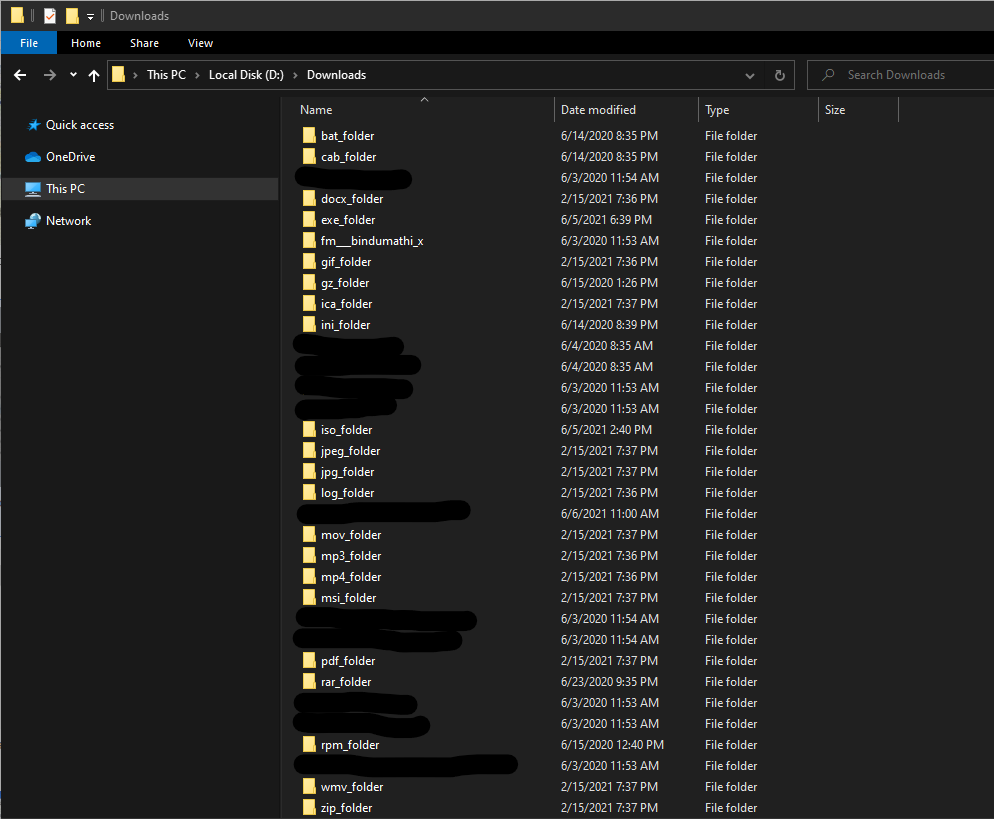
Not only that, How about if we can move a downloaded file to a specific folder at the moment it completes the download?
How cool is that?
I also had these questions and thoughts too.
I wanted to automate this so that I will not have to think about this again.
Following simple Python scrip will do exactly what I wanted. I will explain it to you so that you also will understand it and apply it to your need.
Let’s start.
Libraries Used
We only use the Python Standard Libraries for this and no need to install extra libraries.
Our Imports
We mainly use the os library to access the filesystem, shutil library to move and copy files, and the time library to manage our intervals within the main loop.
from os import listdir
from os.path import isfile, join
import os
import shutil
import time
Set our Variables
Now we define our variables which we will use within the script. In this way, it’s easy for us to manage those when we need changes.
Here we need a variable to store our source location which is the Download folder, then we need another variable to store our destination location, in here you can give any location you desire to have your downloads organized.
sourceFolder = "C:\\Users\\User\\Downloads"
file_type_variation_list = []
filetype_folder_dict = {}
destination_root = "D:\\Downloads"
Defining method to execute our logic
We will now create a method to store our logic and code for the manipulation of files in the Download directory.
def sort_files_in_a_folder(mypath):
now we need to collect the full path of all the files in the Download directory so that we can loop them later in our script. For this, we use the following line of code.
files = [file_name for file in listdir(mypath) if isfile(join(mypath, file_name))]
in above, we loop through all the files in the source directory while checking the validity of the file and assigning it to the file array.
This is why I love Python. Just one line of code, we collected all the file paths to an array.
Now we need to loop through these files to arrange them according to its extension. We need two for loops. One is to create our file extension array, our file type folder dictionary, and creating the folder structure on our destination location.
The second loop is to move the files from source to destination folders based on file extension.
First for Loop
In this, we loop through all the files in our files array. we split the file using dot(.) to get the file extension. Here there could be dots within the file name also, so we use -1 here file.split(‘.’)[-1], to get the last item of the array which is our extension.
for file in files:
filetype = file.split('.')[-1]
After that, we need to make sure that we do not move .tmp files as those are the temporary files created for ongoing downloads. if we move them, our downloads will fail. Hence we check whether the extensions on file_type_variation_list and filetype do not equal to tmp.
if filetype not in file_type_variation_list and filetype != "tmp":
Once the check is completed if that is a new extension, we then need to add it to our extension array file_type_variation_list.
file_type_variation_list.append(filetype)
Now, we need to create our new folder path in order to create our destination location. Also, we need to populate our dictionary variable and map the extension to its folder path. Once done, we use an if condition to check whether the folder exists or not. If not, then we create the folder.
new_folder_name = destination_root + '/' + filetype + '_folder'
filetype_folder_dict[str(filetype)] = str(new_folder_name)
if os.path.isdir(new_folder_name):
continue
else:
os.mkdir(new_folder_name)
Second for Loop
This loop is to find the file extension and move the file to the destination location. Here I have introduced a try block to avoid script crashes if there are issues that occurred during the file move.
We generate the source file path using mypath variable and file variable and get the file extension as we described in the previous loop, then check the new location on our dictionary variable. Finally, we move the file from a source location to a destination.
for file in files:
src_path = mypath + '/' + file
filetype = file.split('.')[-1]
if filetype in filetype_folder_dict.keys():
dest_path = filetype_folder_dict[str(filetype)]
try:
shutil.move(src_path, dest_path)
print(src_path + '>>>' + dest_path)
except shutil.Error as ex:
pass
Our Main Loop
This is the main loop and it keeps running. It checks the file count in the Download folder to determine whether a new file was downloaded. If a new file is downloaded, the old count and the new count will not match and then it calls our method above described to move that file to the destination.
while True:
NumberOfFiles = len(os.listdir(sourceFolder))
time.sleep(20)
OldNumber = NumberOfFiles
NumberOfFiles = len(os.listdir(sourceFolder))
if NumberOfFiles != OldNumber:
sort_files_in_a_folder(sourceFolder)
Full Script
Here I have attached the full script.
from os import listdir
from os.path import isfile, join
import os
import shutil
import time
sourceFolder = "C:\\Users\\User\\Downloads"
file_type_variation_list = []
filetype_folder_dict = {}
destination_root = "D:\\Downloads"
def sort_files_in_a_folder(mypath):
files = [file_name for file in listdir(mypath) if isfile(join(mypath, file_name))]
for file in files:
filetype = file.split('.')[-1]
if filetype not in file_type_variation_list and filetype != "tmp":
file_type_variation_list.append(filetype)
new_folder_name = destination_root + '/' + filetype + '_folder'
filetype_folder_dict[str(filetype)] = str(new_folder_name)
if os.path.isdir(new_folder_name):
continue
else:
os.mkdir(new_folder_name)
for file in files:
src_path = mypath + '/' + file
filetype = file.split('.')[-1]
if filetype in filetype_folder_dict.keys():
dest_path = filetype_folder_dict[str(filetype)]
try:
shutil.move(src_path, dest_path)
print(src_path + '>>>' + dest_path)
except shutil.Error as ex:
pass
while True:
NumberOfFiles = len(os.listdir(sourceFolder))
time.sleep(20)
OldNumber = NumberOfFiles
NumberOfFiles = len(os.listdir(sourceFolder))
if NumberOfFiles != OldNumber:
sort_files_in_a_folder(sourceFolder)
Conclusion
Create a .bat file in order to add this to Windows Scheduler so that It listens to changes to the Download folder, which will trigger our script.
C:\Users\User\AppData\Local\Programs\Python\Python37\python.exe "D:\My Projects\Python\Automation\AutoMoveDownloads\cleanDownloads.py"
